Agile Data Science Pdf Free Download
Full summary
This book is basically a big tutorial, and since there is no point summarising a tutorial, the summary will focus only on the more general parts that talk about agile and data science.
"Agile Data Science is an approach to data science around web application development" — The book
In addition to what the above quote says, the author starts the book by defining Agile Data Science as "a methodology for analytics products development, mixing the best software development practices, but adapting them to the iterative nature of data science".
The Agile Data Science Manifesto
One of the key steps towards Agile Data Science is constantly shipping intermediate output: no matter if something is still a draft or you are not sure the data is correct, ship it to your internal user for validation. This will avoid wasting time on features people do not need, and will also help you spot issues early on. This also means documenting the whole thinking process and not just the final product.
That kind of process will also help reducing technical debt, defined as "a concept in programming that reflects the extra work that arises from building code that is easy to implement in the short run, instead of using the best overall solution".
Since data science development is a very iterative process, it is impossible to determine deadlines beforehand. Instead, agree beforehand with you stakeholders that you cannot give them a precise final date, but that will you ship constant progress reports. These reports do not have to be actual formal reports, but a front-end interface that shows the current shape of your data, which will also help you get constant feedback.
People management
"In Agile, we value generalists over specialists" — Also the book
In a standard data science project, there can be several roles, one for each step of the process. In Agile, we try to make the team leaner, by getting generalists instead of specialists. In general, this means we want someone to be a business developer, marketer, and product manager at the same time, someone else can be the experience designer, interaction designer, and web developer, then a third person can take over the roles of an engineer, data scientist, and researcher, and finally someone to be both a platform engineer and a DevOps Engineer. This means 4 people doing the job of 11. Although there are less people involved, there is a lot of synergy between these functions, so we compensate in productivity.
For this setup to work, it is better to use third-party high-level tools and platforms, instead of developing everything in-house. It will save you a lot of overhead time, so you can focus on what really matters.
If you manage a data science team, focus more on overseeing all the experiments that are happening simultaneously throughout the team, than in handing tasks for each one.
Finally, make sure your developers share their code with each other for peer-review, or code together. This will help finding errors and making code more readable for future users.
Agile tools
The typical data flow comprises at least 5 different types of tools, used in a sequential order.
Collectors: the tools used to collect and log events (events are the occurrences we want to measure, such as clicks and purchases). Ex.: Kafka
Bulk storage: filesystem capable of parallel access by many concurrent proceses. Ex.: Amazon S3 and Hadoop (companies are more and more using Amazon S3 instead of Hadoop).
Distributed document stores: multi-node stores using a document format. Ex.: MongoDB
Application server: it plumbs JSON files from the distributed document store through to the client, allowing for visualisation. Ex.: Python/Flask, Ruby/Sinatra, Node.js.
Browser/application: it displays data visualisation and possibly interactive tools. It can be a dedicated app or an ordinary internet browser, to display HTML pages.
The Data-Value Pyramid
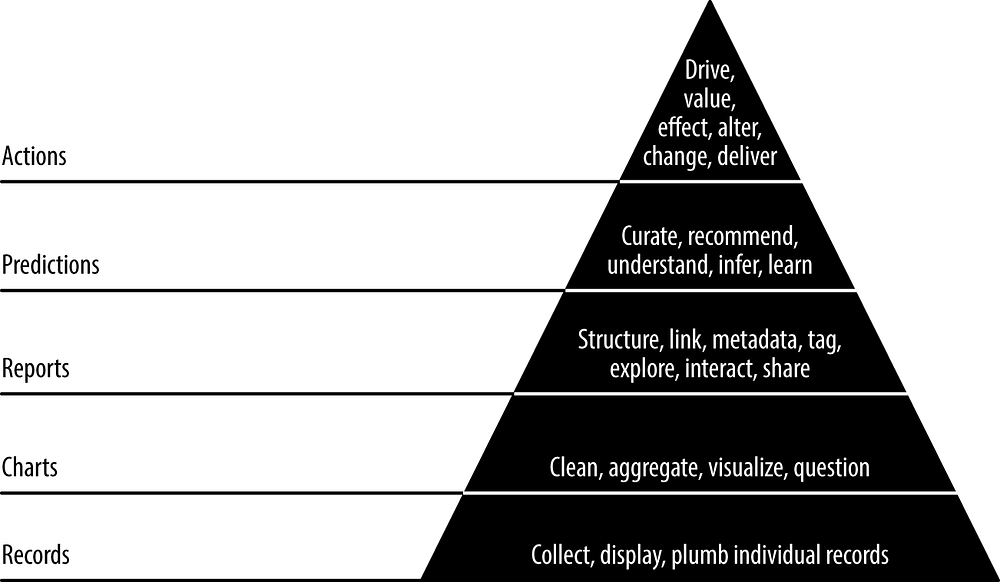
The Data-Value Pyramid shows all the added-value we can get from data in a shape that highlights the importance of foundations: you cannot optimally get value from your reports, for instance, if you have not yet worked properly on plumbing your records and displaying basic charts. This is valid from a project perspective, but also from a company's point of view: companies should have solid foundation on how their records are collected, and sound understanding of basic charts before moving on to building reports or trying to implement recommendation systems. This process allows for constant iteration in each step before moving on to the next. The project built in the book is based on these steps, with the author detailing each of them with examples:
Records
These are the foundation of your pyramid: make sure you are collecting exactly the events you want and make many tests to check for inconsistencies. Then, display those records in a front-end interface and exchange with your stakeholders. This will help you see if you are working with the right data and avoid wasting time in the future.
Charts
Charts are the first and simplest way to have proper visual representation of your data. You probably won't be able to get your charts right at first, so try different approaches and iterate with the feedback you get. In the end, make sure your chart tells a story.
Reports
Reports are a set of charts or tables and other additional information, eventually with interactive features. Make sure you know the kind of information your end users need by exchanging information, and understand how they interact with your report, so you can choose the interactive features. They can be built from the charts you already have.
Predictions
"Prediction is very difficult, especially if it's about the future" — Nils Bohr, Nobel laureate in Physics
Here is where the value of data starts showing: seeing what happened in the past is good, but being able to predict the future is great. The example used in the book is a model that tries to predict flight delays based on time of departure, airport and even aircraft information. There are essentially two types of prediction models out there: regression and classification. Roughly speaking, regression deals with problems where you will have a quantitative output in the end, such as predicting a house price or someone's weight, whereas classification deals with categorical outputs: predicting someone's football team or social class.
Actions
Finally, this is the most important part: information is only worth something if you can act on it. The book does not describe this step, but it could have been a good idea to give some examples of direct action originated by data science. Instead, it ends by improving its predictive model. It is very important to know what actions you will take based on your prediction data, ideally before calculating it. This helps you avoid "vanity metrics": metrics you look at to feel good but don't help you make any decisions.
Posted by: terranceterrancetorruellase0270985.blogspot.com
Source: https://medium.com/dataseries/book-summary-agile-data-science-2-0-f008c6bcfaa7

Post a Comment for "Agile Data Science Pdf Free Download"